x=torch.tensor([[1.,2,3],[4,5,6]])x=torch.zeros(4,8)# 4x8 matrix of all zerosx=torch.ones(4,8)# 4x8 matrix of all onesx=torch.randn(4,8)# 4x8 matrix of iid Normal(0, 1) samples
也可以只分配内存但是不初始化值
1
x=torch.empty(4,8)
tensor memory
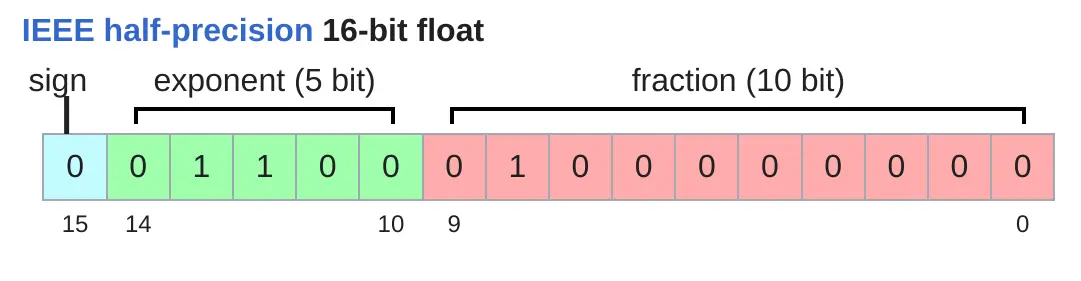
几乎所有的数据都以浮点数的形式存储
float32
float32 data
在大多数情况下,float32 是默认的数据类型
数据的内存占用由数值的数量和数据类型决定
1
2
3
4
5
x=torch.zeros(4,8)assertx.dtype==torch.float32# Default typeassertx.numel()==4*8assertx.element_size()==4# Float is 4 bytesassertget_memory_usage(x)==4*8*4# 128 bytes
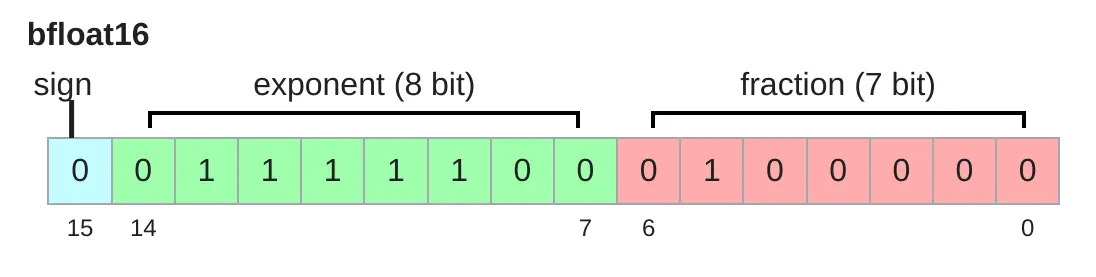
float16
float16 data
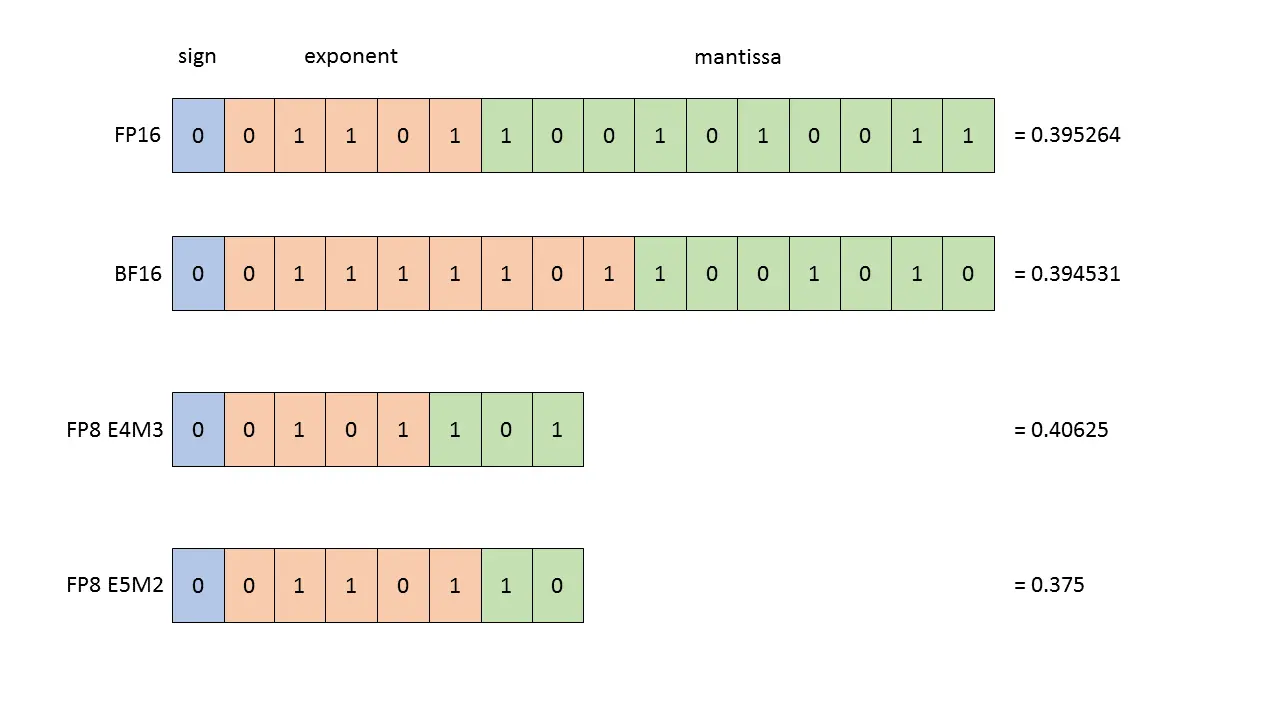
float16 数据大小减半,但是可以表示的数值范围较小
1
2
3
4
x=torch.zeros(4,8,dtype=torch.float16)assertx.element_size()==2x=torch.tensor([1e-8],dtype=torch.float16)assertx==0# Underflow to 0
x=torch.tensor([1e-8],dtype=torch.bfloat16)assertx!=0# No underflow!
fp8
fp8 data
fp8 是另一种为机器学习设计的数据类型
使用float32 时训练效果较有效,但是需要较多的内存
使用 fp8、float16 和 bfloat16 可能导致训练存在风险,模型不稳定
一般可以使用混合精度训练
Compute accounting
tensor on gpus
默认 tensor 是存储在 CPU 上的,我们需要手动将其移动到 GPU
1
2
3
4
5
text("Move the tensor to GPU memory (device 0).")y=x.to("cuda:0")asserty.device==torch.device("cuda",0)text("Or create a tensor directly on the GPU:")z=torch.zeros(32,32,device="cuda:0")
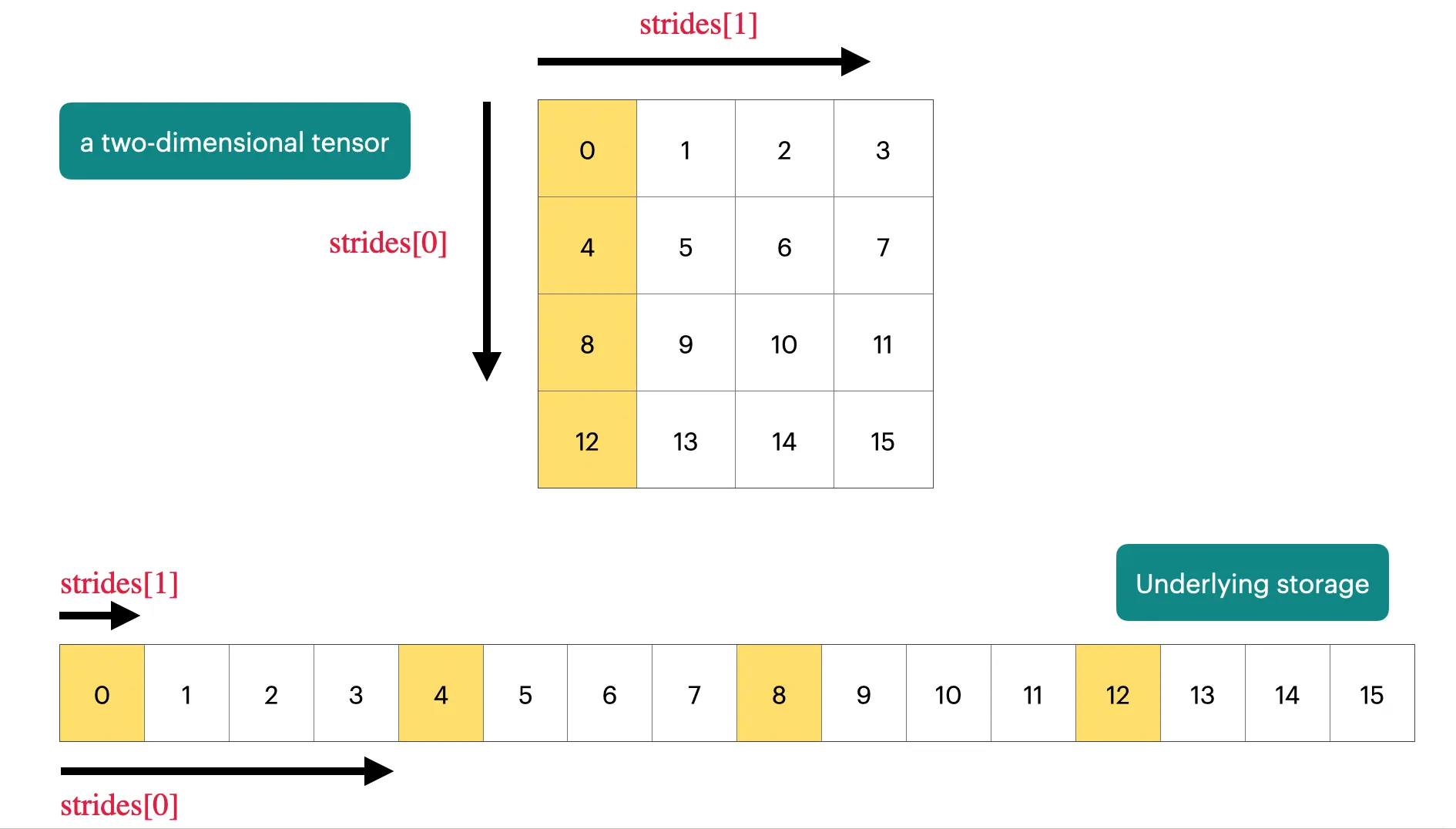
x=torch.tensor([[1.,2,3],[4,5,6]])# @inspect xy=x.transpose(1,0)# @inspect yassertnoty.is_contiguous()try:y.view(2,3)assertFalseexceptRuntimeErrorase:assert"view size is not compatible with input tensor's size and stride"instr(e)# 强制contiguousy=x.transpose(1,0).contiguous().view(2,3)# @inspect yassertnotsame_storage(x,y)
x=torch.tensor([1,4,9])asserttorch.equal(x.pow(2),torch.tensor([1,16,81]))asserttorch.equal(x.sqrt(),torch.tensor([1,2,3]))asserttorch.equal(x.rsqrt(),torch.tensor([1,1/2,1/3]))# i -> 1/sqrt(x_i)asserttorch.equal(x+x,torch.tensor([2,8,18]))asserttorch.equal(x*2,torch.tensor([2,8,18]))asserttorch.equal(x/0.5,torch.tensor([2,8,18]))
对于一个线性模型来说,如果有 B 个数据点,每个数据点是 D 维的,输出是 K 维的。输入数据 x 维度为 (B, D),权值矩阵维度为 (D, K),那么对于每个三元 index(i, j, k),需要进行一次乘法运算 x[i][j] * w[j][k],以及一个加法运算。总的 FLOPs 是 2 * B * D * K
前向传播中的 FLOPs 近似为 2 * 数据量 * 参数量
Model FLOPs utilization(MFU):真实的 FLOP/s 除以额定 FLOP/s
gradients basics
PyTorch 中梯度计算非常简单,假定我们有一个线性模型 $y = 0.5 (x w - 5)^2$
classLinear(nn.Module):"""Simple linear layer."""def__init__(self,input_dim:int,output_dim:int):super().__init__()self.weight=nn.Parameter(torch.randn(input_dim,output_dim)/np.sqrt(input_dim))defforward(self,x:torch.Tensor)->torch.Tensor:returnx@self.weightclassCruncher(nn.Module):def__init__(self,dim:int,num_layers:int):super().__init__()self.layers=nn.ModuleList([Linear(dim,dim)foriinrange(num_layers)])self.final=Linear(dim,1)defforward(self,x:torch.Tensor)->torch.Tensor:# Apply linear layersB,D=x.size()forlayerinself.layers:x=layer(x)# Apply final headx=self.final(x)assertx.size()==torch.Size([B,1])# Remove the last dimensionx=x.squeeze(-1)assertx.size()==torch.Size([B])returnx
默认 CPU tensor 被放置在 paged memory 中,我们可以手动 pin,这样就可以实现异步将 tensor 从 CPU 移动到GPU